
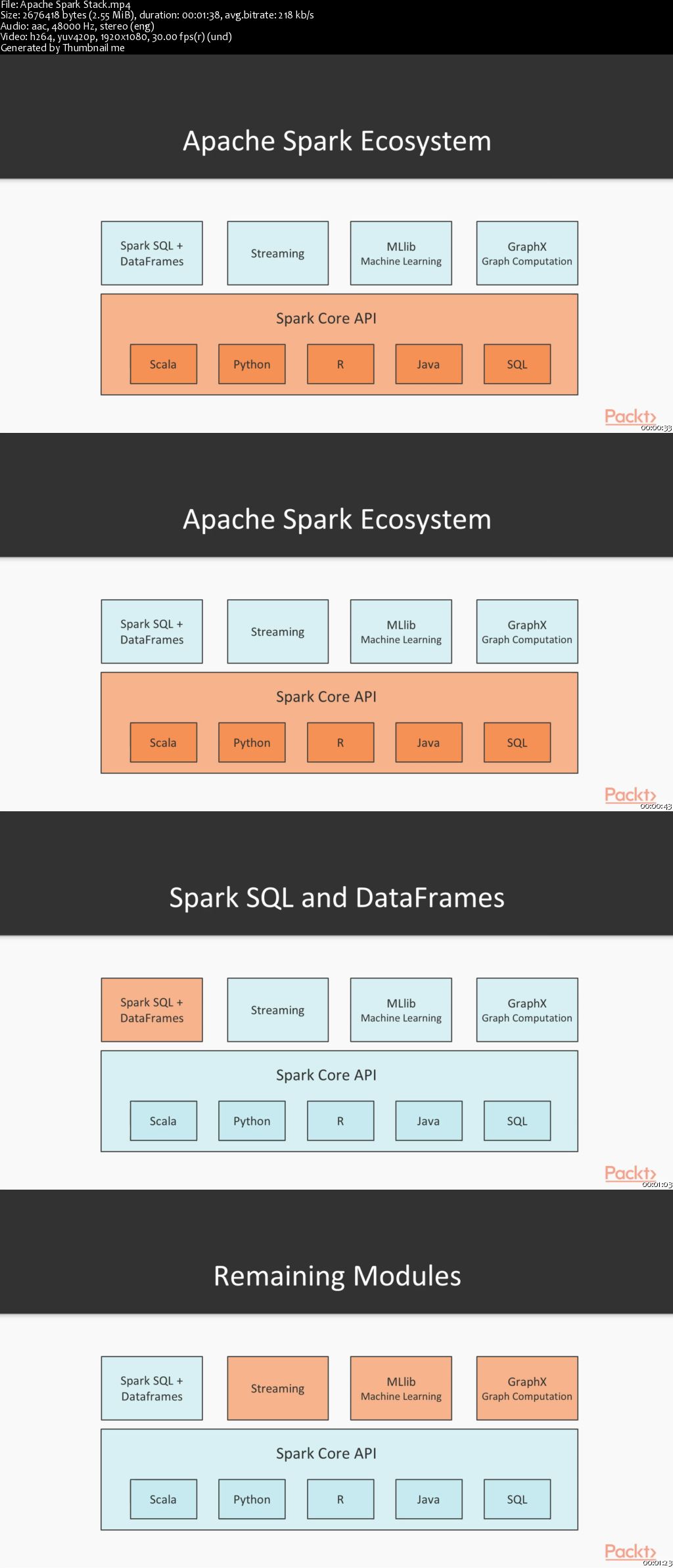
Apache Spark is an open-source distributed engine for querying and processing data. In this tutorial, we provide a brief overview of Spark and its stack. This tutorial presents effective, time-saving techniques on how to leverage the power of Python and put it to use in the Spark ecosystem. You will start by getting a firm understanding of the Apache Spark architecture and how to set up a Python environment for Spark.
You’ll learn about different techniques for collecting data, and distinguish between (and understand) techniques for processing data. Next, we provide an in-depth review of RDDs and contrast them with DataFrames. We provide examples of how to read data from files and from HDFS and how to specify schemas using reflection or programmatically (in the case of DataFrames). The concept of lazy execution is described and we outline various transformations and actions specific to RDDs and DataFrames.
Finally, we show you how to use SQL to interact with DataFrames. By the end of this tutorial, you will have learned how to process data using Spark DataFrames and mastered data collection techniques by distributed data processing.
Download rapidgator
https://rg.to/file/fe6964309548f20b58239d44f8760162/Learning_PySpark_%5BVideo%5D.rar.html
Download nitroflare
http://nitroflare.com/view/77473E680C6DF45/Learning_PySpark__Video_.rar
Download 百度云
链接: https://pan.baidu.com/s/1kXpG107 密码: skdn
转载请注明:0daytown » Learning PySpark